AI落地的技术挑战
企业在拥抱人工智能的过程中,通常面临算力、模型、应用等多层面的挑战,阻碍企业智能化转型进程。
资源管理复杂
大量异构算力资源、复杂的高速网络调度以及海量数据管理,将比传统计算业务更加复杂,AI 任务出错比例高,往往需要全栈工程师来进行配置和支持,交付周期长,风险大,成本高。
算力管理不敏捷
传统GPU独占技术方案,限制了资源的使用效率,造成数据中心资源的整体浪费。这种低效的资源利用模式在面对AI推理场景时尤为明显,亟需更精细的调度技术优化资源分配,提高算力管理敏捷度。
生态整合交付复杂
AI 的蓬勃发展带来了大量的新兴技术公司,在各个领域都有创新技术,打包组合形成整体解决方案将有助于客户快速提升业务能力。
拥抱大模型门槛高
企业采用大型模型时,面临知识门槛高、资源成本高和人才短缺等挑战,增加了技术实施的复杂性和经济负担。亟需易于接入且具有成本效益的解决方案,以加速企业对大型模型的应用和落地。
运营专业复杂
GPU 算力投资巨大,客户的 AI 服务访问场景多样化,传统的模式往往计费形式固化不灵活、用户沟通时间长,导致客户无法快速获取计算和评估成本,造成用户流失的可能。
模型开发困难
模型开发是一个涵盖数据标注、算法编写、模型构建和训练等环节的复杂过程,不仅耗时且需经过多轮迭代和优化,对企业来说技术要求较高。需引入专业的工具和平台以简化模型开发流程、降低技术门槛。
快速形成应用场景
行业 AI 场景迭代快、产品组合多,新兴的 AI 分析场景支持困难,所以需要把模型、数据集和算力调度快速结合,而这些将要求算力中心有更高的起步门槛。
开发效率低
企业在开发过程中常遇到模型调用接口不一致、参数标准化程度低以及提示词格式多样化等难题。一个提供可视化智能体编排、统一API管理及标准化提示词模板的一站式平台,能够显著提高智能体开发的效率。
核心功能
- Core functions -

异构算力协同
多区多类型GPU算力/通用算力/网络资源(IB、RoCE)/存储资源(NVMe、并行文件存储和对象存储)的统一调度管理,支持GPU Direct、NVLink等技术,支持从模型微调到训练的全场景业务需求。

智能算力调度
具备千卡万卡的分布式调度与管理能力,支持优先级/预留/暂停/恢复/公平共享和抢占式调度;个性化安置组策略自动分配和管理算力资源,大幅缩短任务执行时间;算力资源按应用、按需随时匹配,自动切换。

算力池化与精分
支持组建共享算力池和专属算力池;支持显卡多实例、直通(单卡、多卡)、vGPU方案,部分卡支持显存算力资源细粒度切分,有效保证隔离性和安全性;轻松应对不同颗粒度的算力资源需求。

一站式AI计算
提供算法代码编写、模型训练、模型微调、模型管理、模型部署推理等服务;提供镜像仓库/函数库/驱动/深度学习框架/数据集等支持;集成行业内多家厂商生态应用,助力用户全场景的AI业务实现落地。
故障检测与自愈
通过统一运维管理平台,规范化、可视化高效运维资源,帮助管理员实现精细化资源分配,结合多维资源监控,发现故障、启动自愈服务,减少运时间,提高算力利用效率。
全流程自服务式供给
提供用户自助服务能力,包括账户创建、账户充值、资源申请、在线开通、资源使用再到资源释放的全流程服务。可选共享资源按任务占用卡时结算或专属资源按配置结算,提升用户使用体验和资源供给效率。
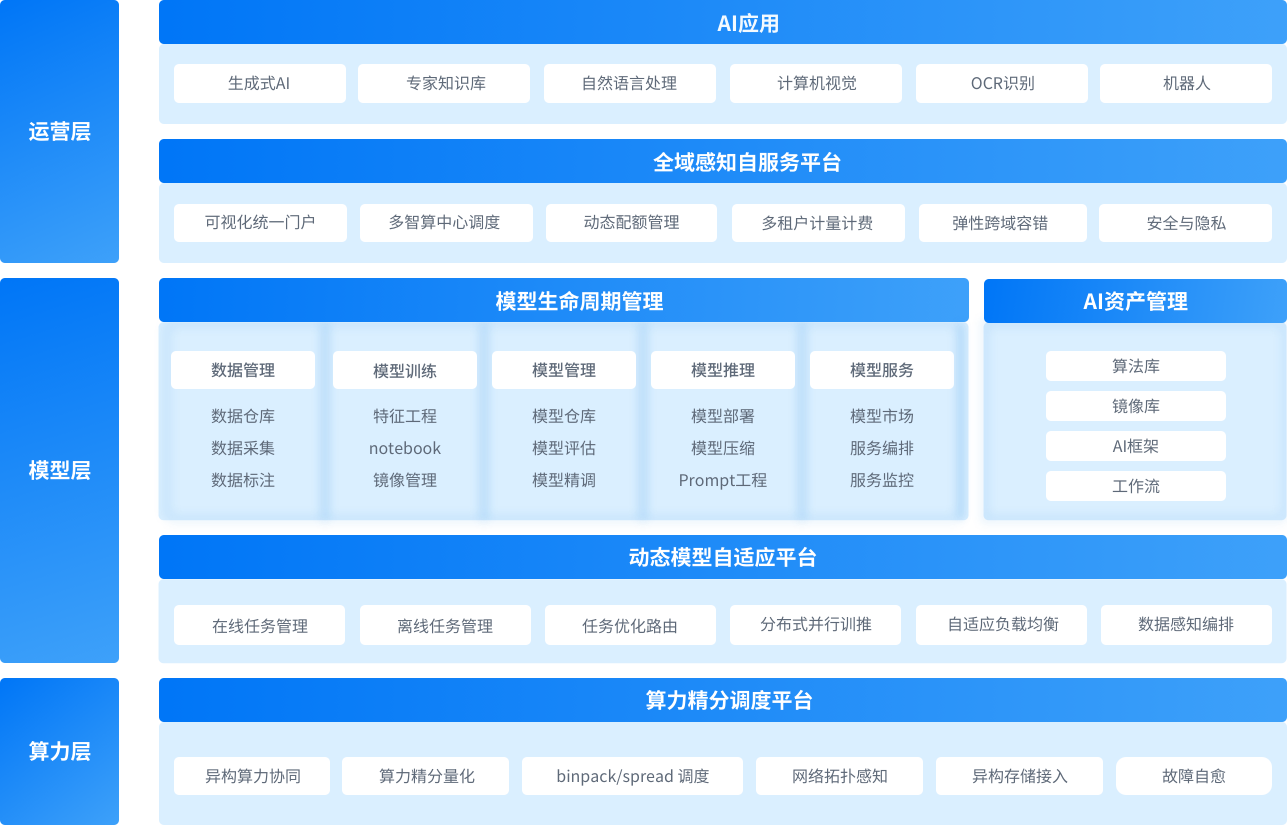
产品架构
- Architecture -